عندما تملأ مجموعة Hadoop الخاصة بك بكميات كبيرة من البيانات الخام ، ومحللو البيانات والعلماء لديك يشدون على البدء. ثم يطرأ عليك السؤال: كيف ستخزن كل هذه البيانات حتى يتمكنوا من استخدامها بالفعل؟
والخبر السار هو أن Hadoop هي واحدة من أكثر الطرق فعالية من حيث التكلفة لتخزين كميات هائلة من البيانات. يمكنك تخزين جميع أنواع البيانات المهيكلة وشبه الهيكلية وغير المهيكلة داخل نظام الملفات الموزعة Hadoop ، ومعالجتها بعدة طرق باستخدام Hive و HBase و Spark والعديد من المحركات الأخرى.
لديك العديد من الخيارات عندما يتعلق الأمر بتخزين البيانات ومعالجتها على Hadoop ، والتي يمكن أن تكون نعمة ونقمة. قد تصل البيانات إلى مجموعة Hadoop بتنسيق يمكن قراءته بواسطة الإنسان مثل JSON أو XML ، أو كملف CSV ، لكن هذا لا يعني أن هذه هي أفضل طريقة لتخزين البيانات بالفعل.
في الواقع ، تخزين البيانات في Hadoop باستخدام تلك التنسيقات الأولية غير فعال بشكل رهيب. بالإضافة إلى ذلك ، لا يمكن تخزين تنسيقات الملفات هذه بطريقة متوازية. نظرًا لأنك تستخدم Hadoop في المقام الأول ، فمن المحتمل أن تكون كفاءة التخزين والتوازي على رأس قائمة الأولويات ، مما يعني أنك بحاجة إلى شيء آخر.
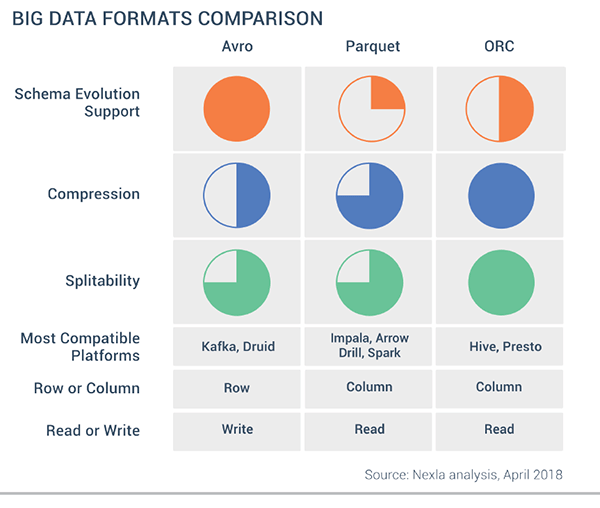
لحسن الحظ بالنسبة لك ، استقر مجتمع البيانات الضخمة أساسًا على ثلاثة تنسيقات ملفات محسنة للاستخدام في مجموعات Hadoop: Optimized Row Columnar (ORC) و Avro و Parquet. بينما تشترك تنسيقات الملفات هذه في بعض أوجه التشابه ، فإن كل واحدة منها فريدة من نوعها وتجلب مزاياها وعيوبها النسبية.
للحصول على أدنى مستوى من هذه التقنية العالية ، استفدنا من معرفة الأشخاص الأذكياء في Nexla ، مطور أدوات لإدارة البيانات وتحويل التنسيقات. Nexla CTO والمؤسس المشارك جيف ويليامز وأفيناش شادادبوري ، رئيس البيانات والبنية التحتية في Nexla ، كانوا لطفاء بما يكفي ليشرحوا لـ Certi.news ما يحدث مع ORC و Avro و Parquet :
- Avro هو تنسيق قائم على الصفوف. تم إنشاؤه بواسطة Apache. يحتوي كل سجل على رأس يصف هيكل البيانات في السجل. يتم تخزين هذا العنوان بتنسيق JSON. يتم تخزين البيانات كمعلومات ثنائية. يستخدم التطبيق المعلومات الموجودة في الرأس لتحليل البيانات الثنائية واستخراج الحقول التي تحتوي عليها. Avro هو تنسيق جيد لضغط البيانات وتقليل متطلبات التخزين وعرض النطاق الترددي للشبكة.
- ينظم ORC (التنسيق الأمثل لأعمدة الصفوف) البيانات في أعمدة بدلاً من صفوف. تم تطويره بواسطة HortonWorks لتحسين عمليات القراءة والكتابة في Apache Hive هو نظام مستودع بيانات يدعم التلخيص السريع للبيانات والاستعلام عبر مجموعات البيانات الكبيرة). يحتوي ملف ORC على شرائط من البيانات. يحتفظ كل شريط ببيانات عمود أو مجموعة من الأعمدة. يحتوي الشريط على فهرس في الصفوف الموجودة في الشريط ، وبيانات كل صف ، وتذييل يحتوي على معلومات إحصائية (العدد ، والمجموع ، والحد الأقصى ، والدقيقة ، وما إلى ذلك) لكل عمود.
- Parquet هو تنسيق بيانات عمودي آخر. تم إنشاؤه بواسطة Cloudera و Twitter. يحتوي ملف باركيه على مجموعات صفوف. يتم تخزين البيانات الخاصة بكل عمود معًا في نفس مجموعة الصفوف. تحتوي كل مجموعة صفوف على قطعة واحدة أو أكثر من البيانات. يتضمن ملف باركيه بيانات وصفية تصف مجموعة الصفوف الموجودة في كل مقطع. يمكن لأي تطبيق استخدام بيانات التعريف هذه لتحديد موقع المقطع الصحيح لمجموعة معينة من الصفوف بسرعة ، واسترداد البيانات في الأعمدة المحددة لهذه الصفوف. باركيه متخصص في تخزين ومعالجة أنواع البيانات المتداخلة بكفاءة. وهو يدعم أنظمة الضغط والتشفير الفعالة للغاية.
اوجه التشابه
تم تحسين جميع التنسيقات الثلاثة للتخزين على Hadoop ، وتوفر درجة معينة من الضغط. عندما تنفق عشرات الآلاف من الدولارات لشراء نظام قرص موزع لتخزين تيرابايت أو بيتابايت من البيانات ، فإن الضغط هو عامل مهم للغاية.
ORC و Parquet و Avro هي أيضًا تنسيقات ثنائية يمكن قراءتها آليًا ، وهذا يعني أن الملفات تبدو مثل طلاسم للبشر. إذا كنت بحاجة إلى تنسيق يمكن قراءته من قبل الإنسان مثل JSON أو XML ، فمن المحتمل أن تعيد النظر في سبب استخدامك لبرنامج Hadoop في المقام الأول.
يمكن تقسيم الملفات المخزنة بتنسيقات ORC و Parquet و Avro عبر عدة أقراص ، مما يفسح المجال لقابلية التوسع والمعالجة المتوازية. لا يمكنك تقسيم ملفات JSON و XML ، وهذا يحد من قابليتها للتوسع والتوازي.
جميع التنسيقات الثلاثة تحمل مخطط البيانات في الملفات نفسها ، وهذا يعني أنها موصوفة ذاتيًا. يمكنك أخذ ملف ORC أو Parquet أو Avro من مجموعة واحدة وتحميله على جهاز مختلف تمامًا ، وسوف يعرف الجهاز ماهية البيانات وسيكون قادرًا على معالجتها.
بالإضافة إلى كونها تنسيقات ملفات ، فإن ORC و Parquet و Avro هي أيضًا تنسيقات متصلة بالسلك ، مما يعني أنه يمكنك استخدامها لتمرير البيانات بين العقد في مجموعة Hadoop cluster الخاصة بك.
اوجه الاختلاف
يتمثل الاختلاف الأكبر بين ORC و Avro و Parquet في كيفية تخزين البيانات. يقوم كل من Parquet و ORC بتخزين البيانات في أعمدة ، بينما يقوم Avro بتخزين البيانات بتنسيق قائم على الصفوف. بحكم طبيعتها ، يتم تحسين مخازن البيانات الموجهة نحو الأعمدة لأحمال العمل التحليلية المليئة بالقراءة ، في حين أن قواعد البيانات المستندة إلى الصفوف هي الأفضل لأحمال عمل المعاملات الكثيفة الكتابة.
من أجل شرح الفرق بين تخزين الصفوف والعمود ، استخدم مثالًا لشركة كبيرة بها مليون موظف ، حيث يريد مسؤول تنفيذي العثور على الرواتب المدفوعة للعمال مجمعة حسب كل موقع. إذا تم تخزين مجموعات بيانات الراتب والموقع بطريقة موجهة نحو الأعمدة ، فهذا استعلام بسيط نسبيًا يحتاج فقط إلى فحص البيانات في هذين العمودين.
ولكن إذا كنت تريد القيام بصفوف صف ، فعليك إحضار ملايين الصفوف والقيام بالعملية على كل من الصفوف . "في تلك المواقف التي تحاول فيها إجراء إسقاط على عدد قليل جدًا من الأعمدة من مجموعة البيانات بأكملها ، يكون العمود الرأسي أفضل بكثير مقارنة بالتنسيق المستند إلى الصف.
يعتمد تنسيق الملف الذي تستخدمه جميعًا على حالة الاستخدام المحددة. بينما تتفوق المتاجر الموجهة نحو الأعمدة مثل Parquet و ORC في بعض الحالات ، في حالات أخرى ، قد تكون آلية التخزين القائمة على الصفوف مثل Avro هي الخيار الأفضل.
يقول ويليامز: "لنفترض أنك تقدم رحلات طيران متاحة إلى مستخدم على صفحة ويب". "هذا مجرد صراخ لاستخدام التخزين المستند إلى الصفوف لأنك سترغب في الحصول على الكثير من المعلومات حول كل إدخال معين وربما تريد الحصول على الكثير من الإدخالات المتجاورة ، مثل قول جميع الإدخالات من الساعة 9 هذا الصباح إلى الساعة 1 بعد الظهر. هذا استعلام SQL كلاسيكي يستند إلى صفوف ".
نظرًا للطريقة التي يتم بها تحسين البيانات للاسترجاع السريع ، تقدم المتاجر القائمة على الأعمدة ، Parquet و ORC ، معدلات ضغط أعلى من تنسيق Avro المستند إلى الصفوف, قد يؤدي ذلك إلى قلب الموازين نحو استخدام تنسيقات الملفات هذه عندما تصبح البيانات كبيرة بشكل خاص.
إذا كان لديك تطبيق تقوم فيه فقط بجمع كميات هائلة من البيانات ، مثل إنترنت الأشياء ، وكنت قلقًا بشأن تكاليف التخزين ، فقد تنظر إلى متجر عمودي لأنه عندما تخزن كل هذه القيم بنفس النوع بجوار بعضها البعض ، يتيح لك ذلك الضغط عليها بشكل أكثر كفاءة مما لو كنت تخزن صفوفًا من البيانات "، كما يقول. "سترى غالبًا تحسين التخزين كسبب لدفع الأشخاص إلى المتاجر العمودية."
هناك جانب آخر يجب مراعاته وهو دعم تطور المخطط ، أو القدرة على تغيير بنية الملف بمرور الوقت. من بين التنسيقين العموديين ، تقدم ORC تطورًا أفضل للمخطط ، وفقًا لـ Nexla. ومع ذلك ، تقدم Avro تطورًا فائقًا للمخطط بفضل استخدامه المبتكر لـ JSON لوصف البيانات ، أثناء استخدام التنسيق الثنائي لتحسين حجم التخزين.
حالات استخدام
قد يكون العثور على تنسيق الملف المناسب لمجموعة البيانات الخاصة بك أمرًا صعبًا. بشكل عام ، إذا كانت البيانات واسعة ، وتحتوي على عدد كبير من السمات وثقيلة الكتابة ، فقد يكون النهج المستند إلى الصف هو الأفضل. إذا كانت البيانات أضيق ، وتحتوي على عدد أقل من السمات ، وتكون ثقيلة القراءة ، فقد يكون النهج المستند إلى العمود هو الأفضل.
في بعض الأحيان ، قد يلتزم مستخدمو Hadoop بتنسيق قائم على العمود ORC أو Parquet ولكن عندما يبدأون في الدخول في مشروع ، يبدأ نمط الإدخال / الإخراج في التحول نحو وجود أكثر كثافة في الكتابة. في هذه الحالة ، قد يكون من الأفضل التبديل إلى التخزين المستند إلى الصفوف Avro مع إضافة فهارس توفر أداء قراءة أفضل.
تطبيقات Hadoop المختلفة لها أيضًا صلات مختلفة لتنسيقات الملفات الثلاثة. يتم استخدام ORC بشكل شائع مع Apache Hive ، وبما أن Hive تدار بشكل أساسي من قبل المهندسين العاملين في Hortonworks ، تميل بيانات ORC إلى الوجود في الشركات التي تدير (Hortonworks Data Platform (HDP).) . يرتبط Presto أيضًا بملفات ORC.
وبالمثل ، يستخدم Parquet بشكل شائع مع Impala ، وبما أن Impala هو مشروع Cloudera ، فهو موجود بشكل شائع في الشركات التي تستخدم Cloudera Distribution of Hadoop (CDH). يستخدم Parquet أيضًا في Apache Drill ، وهو حل SQL-on-Hadoop المفضل لدى MapR ؛ Arrow ، تنسيق الملفات الذي أيده Dremio ؛ و Apache Spark ، محرك البيانات الضخمة المفضل لدى الجميع والذي يفعل القليل من كل شيء.
Avro ، على سبيل المقارنة ، هو تنسيق الملف الذي يوجد غالبًا في مجموعات Apache Kafka ، وفقًا لـ Nexla. Avro هو أيضًا تنسيق ملف البيانات الضخمة المفضل الذي يستخدمه Druid ، منصة الحوسبة وتخزين البيانات الضخمة عالية الأداء التي خرجت من Metamarkets وتم التقاطها في النهاية بواسطة Yahoo.
يعد تنسيق الملف الذي تستخدمه لتصميم حل البيانات الضخمة أمرًا مهمًا ، ولكنه مجرد اعتبار واحد من بين العديد من الاعتبارات .