Apache Hadoop هو إطار عمل برمجي مفتوح المصدر يقوم بتخزين البيانات بطريقة موزعة ومعالجة تلك البيانات بالتوازي. يوفر Hadoop طبقة التخزين الأكثر موثوقية في العالم - HDFS ، محرك معالجة الدفعات - MapReduce وطبقة إدارة الموارد - YARN . في هذا البرنامج التعليمي حول "كيف يعمل Hadoop داخليًا" ، سوف نتعلم ما هو Hadoop ، وكيف يعمل Hadoop ، والمكونات المختلفة لـ Hadoop ، والشياطين في Hadoop ، وأدوار HDFS ، و MapReduce ، و Yarn في Hadoop وخطوات مختلفة لفهم كيفية عمل Hadoop.
كيف يعمل Hadoop داخليا - داخل Hadoop
ما هو Hadoop؟
قبل تعلم كيفية عمل Hadoop ، دعنا نفرش مفهوم Hadoop الأساسي. Apache Hadoop عبارة عن مجموعة من الأدوات المساعدة للبرامج مفتوحة المصدر. إنها تسهل استخدام شبكة من العديد من أجهزة الكمبيوتر لحل المشكلات التي تنطوي على كميات هائلة من البيانات. يوفر إطارًا برمجيًا للتخزين الموزع والحوسبة الموزعة. يقسم الملف إلى عدد الكتل ويخزنه عبر مجموعة من الأجهزة. يحقق Hadoop أيضًا التسامح مع الخطأ من خلال تكرار الكتل على الكتلة. يقوم بمعالجة موزعة بتقسيم الوظيفة إلى عدد من المهام المستقلة. تعمل هذه المهام بالتوازي على كتلة الكمبيوتر.
مكونات ومجالات Hadoop
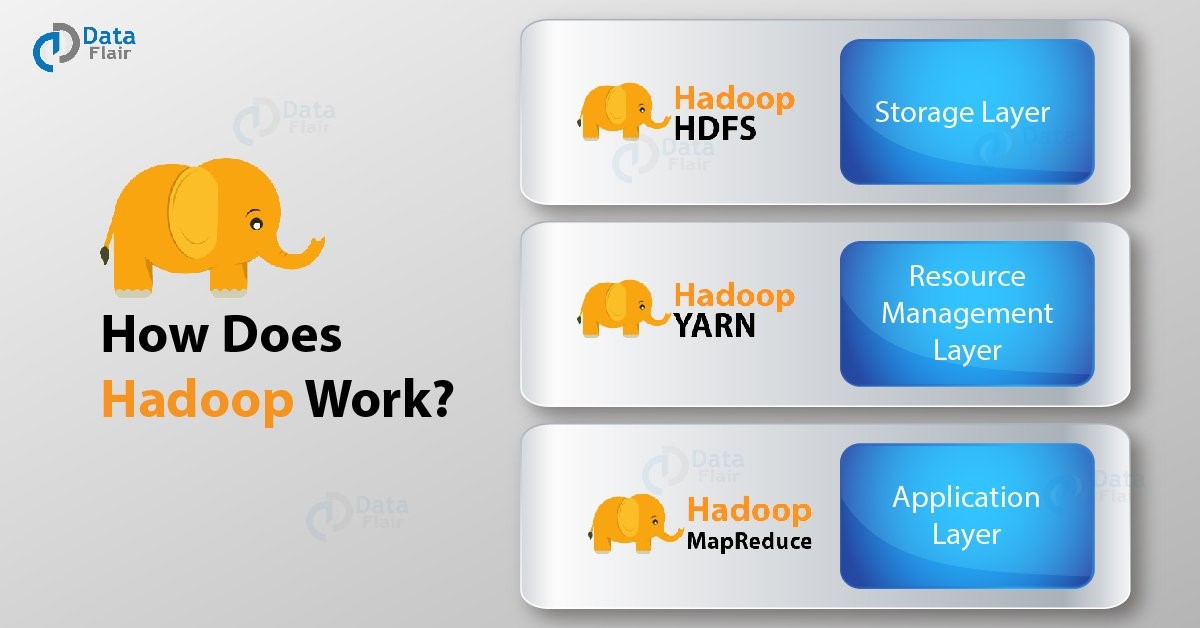
لا يمكنك فهم عمل Hadoop دون معرفة مكوناته الأساسية. إذن ، Hadoop يتكون من ثلاث طبقات (مكونات أساسية) وهي: -
HDFS - يوفر نظام الملفات الموزعة Hadoop لتخزين Hadoop. كما يوحي الاسم ، فإنه يخزن البيانات بطريقة موزعة. يتم تقسيم الملف إلى عدد من الكتل التي تنتشر عبر مجموعة الأجهزة السلعية.
MapReduce - هذا هو محرك المعالجة لبرنامج Hadoop. يعمل MapReduce على مبدأ المعالجة الموزعة . يقسم المهمة المرسلة من قبل المستخدم إلى عدد من المهام الفرعية المستقلة. يتم تنفيذ هذه المهام الفرعية بالتوازي وبالتالي زيادة الإنتاجية.
الغزل - توفر إدارة موارد أخرى r إدارة الموارد لـ Hadoop. هناك نوعان من الشياطين يعملان من أجل الغزل. أحدهما هو NodeManager على الأجهزة التابعة والآخر هو مدير الموارد على العقدة الرئيسية. يعتني الغزل بتخصيص الموارد بين مختلف العبيد الذين يتنافسون عليه.
تعرف على جميع مكونات نظام Hadoop البيئي في 7 دقائق فقط.
Daemons هي العمليات التي تعمل في الخلفية. Hadoop Daemons هي: -
أ) Namenode - يعمل على عقدة رئيسية لـ HDFS.
ب) Datanode - يعمل على العقد التابعة لـ HDFS.
ج) مدير الموارد - يعمل على عقدة YARN الرئيسية لـ MapReduce.
د) مدير العقدة - يعمل على عقدة YARN التابعة لـ MapReduce.
تعمل هذه الشياطين الأربعة لـ Hadoop حتى تكون وظيفية.
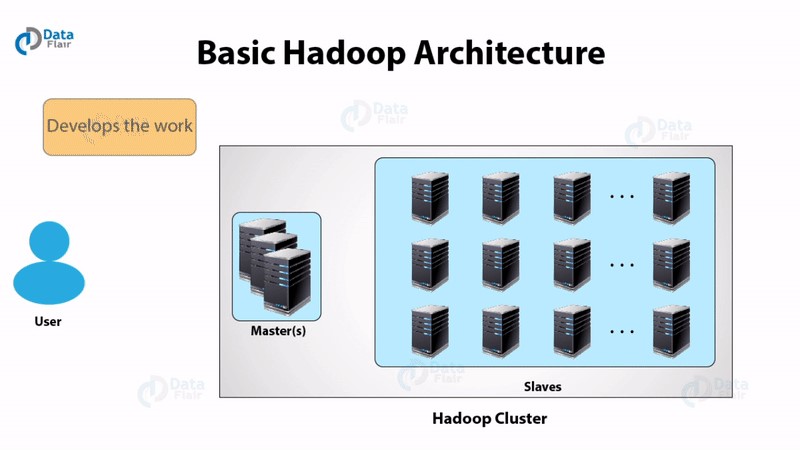
كيف يعمل Hadoop؟
يقوم Hadoop بمعالجة موزعة لمجموعات البيانات الضخمة عبر مجموعة خوادم السلع ويعمل على أجهزة متعددة في وقت واحد. لمعالجة أي بيانات ، يرسل العميل البيانات والبرنامج إلى Hadoop. يقوم HDFS بتخزين البيانات بينما تقوم MapReduce بمعالجة البيانات ويقوم Yarn بتقسيم المهام.
دعونا نناقش بالتفصيل كيف يعمل Hadoop -
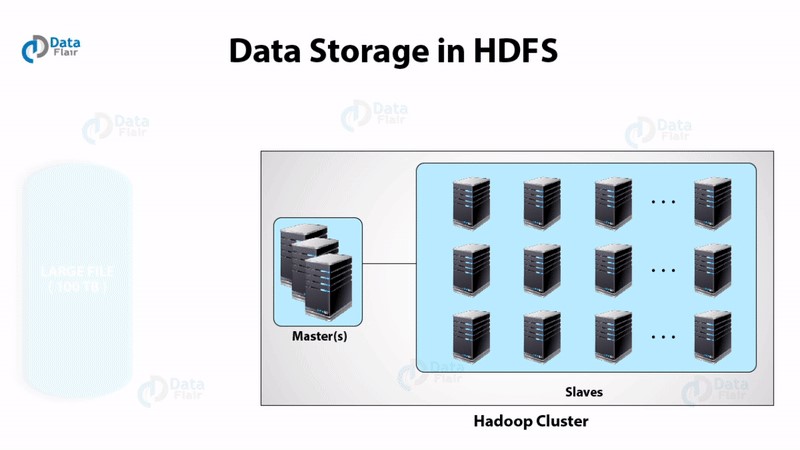
أولا . HDFS
يحتوي نظام الملفات الموزعة Hadoop على طوبولوجيا السيد والعبد . لديها اثنين من الشيطان قيد التشغيل ، وهما NameNode و DataNode.
NameNode
NameNode هو البرنامج الخفي الذي يعمل على الجهاز الرئيسي. إنه حجر الزاوية في نظام ملفات HDFS. يقوم NameNode بتخزين شجرة الدليل لجميع الملفات في نظام الملفات. يتتبع المكان الذي توجد فيه بيانات الملف عبر الكتلة. لا يقوم بتخزين البيانات الموجودة في هذه الملفات.
عندما تريد تطبيقات العميل إضافة / نسخ / نقل / حذف ملف ، فإنها تتفاعل مع NameNode. تستجيب NameNode للطلب المقدم من العميل من خلال إعادة قائمة بخوادم DataNode ذات الصلة حيث توجد البيانات.
DataNode
يعمل برنامج DataNode الخفي على العقد التابعة. يقوم بتخزين البيانات في HadoopFileSystem. في نظام الملفات الوظيفي يتم نسخ البيانات عبر العديد من DataNodes.
عند بدء التشغيل ، يتصل DataNode بـ NameNode. يستمر في البحث عن الطلب من NameNode للوصول إلى البيانات. بمجرد أن توفر NameNode موقع البيانات ، يمكن لتطبيقات العميل التحدث مباشرة إلى DataNode ، أثناء نسخ البيانات ، يمكن لمثيلات DataNode التحدث مع بعضها البعض.
وضع النسخة المتماثلة
يحدد موضع النسخة المتماثلة موثوقية وأداء HDFS. تحسين وضع النسخ المتماثلة يجعل HDFS بعيدًا عن الأنظمة الموزعة الأخرى. يتم تشغيل مثيلات HDFS الضخمة على مجموعة من أجهزة الكمبيوتر المنتشرة عبر العديد من الرفوف. يجب أن يمر الاتصال بين العقد الموجودة على الرفوف المختلفة عبر المفاتيح. في الغالب ، يكون عرض النطاق الترددي للشبكة بين العقد الموجودة على نفس الرف أكبر من النطاق الترددي للشبكة بين الأجهزة الموجودة على رفوف منفصلة.
تحدد خوارزمية إدراك الحامل معرف الحامل لكل DataNode . بموجب سياسة بسيطة ، يتم وضع النسخ المتماثلة على رفوف فريدة. هذا يمنع فقدان البيانات في حالة فشل الحامل. أيضًا ، يستخدم النطاق الترددي من رفوف متعددة أثناء قراءة البيانات. ومع ذلك ، فإن هذه الطريقة تزيد من تكلفة عمليات الكتابة.
لنفترض أن عامل النسخ هو ثلاثة. افترض أن سياسة التنسيب الخاصة بـ HDFS تضع نسخة متماثلة واحدة على رف محلي ونسختين متماثلتين أخريين على جهاز التحكم عن بُعد ولكن نفس الحامل. تعمل هذه السياسة على قطع حركة مرور الكتابة بين الرفوف وبالتالي تحسين أداء الكتابة. تكون فرص فشل الحامل أقل من فرص فشل العقدة. ومن ثم فإن هذه السياسة لا تؤثر على موثوقية البيانات وتوافرها. ولكنه يقلل من النطاق الترددي الكلي للشبكة المستخدم عند قراءة البيانات. هذا بسبب وضع الكتلة في اثنين فقط من الرفوف الفريدة بدلاً من ثلاثة.
ثانيا. مابريديوس
الفكرة العامة لخوارزمية MapReduce هي معالجة البيانات بالتوازي على المجموعة الموزعة. ثم يتم دمجها في النتيجة أو المخرجات المرغوبة.
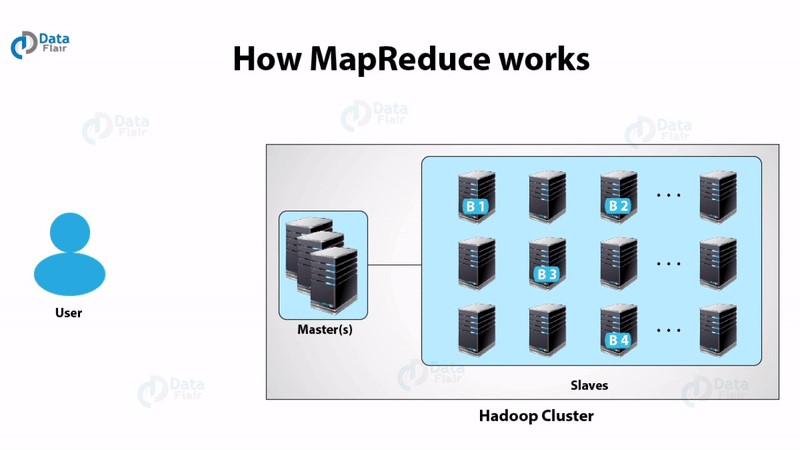
يتضمن Hadoop MapReduce عدة مراحل:
- في الخطوة الأولى ، يحدد البرنامج ويقرأ "ملف الإدخال" الذي يحتوي على البيانات الأولية.
- نظرًا لأن تنسيق الملف عشوائي ، فهناك حاجة لتحويل البيانات إلى شيء يمكن للبرنامج معالجته. يقوم "InputFormat" و "RecordReader" (RR) بهذه المهمة.
يستخدم InputFormat وظيفة InputSplit لتقسيم الملف إلى أجزاء أصغر
ثم يقوم RecordReader بتحويل البيانات الأولية للمعالجة بواسطة الخريطة. يقوم بإخراج قائمة من أزواج المفتاح والقيمة.
بمجرد أن يقوم المخطط بمعالجة أزواج المفتاح والقيمة هذه ، تنتقل النتيجة إلى «OutputCollector». هناك وظيفة أخرى تسمى "Reporter" والتي تنبه المستخدم عند انتهاء مهمة التعيين.
- في الخطوة التالية ، تقوم وظيفة Reduce بتنفيذ مهمتها على كل زوج من المفاتيح والقيمة من مصمم الخرائط.
- أخيرًا ، تنظم OutputFormat أزواج القيمة الرئيسية من Reducer لكتابتها على HDFS.
- نظرًا لكونه قلب نظام Hadoop ، يقوم Map-Reduce بمعالجة البيانات بطريقة مرنة للغاية ومتسامحة مع الأخطاء.
ثالثا. غزل
يقسم الغزل المهمة المتعلقة بإدارة الموارد وجدولة / مراقبة الوظائف إلى شياطين منفصلة. يوجد ResourceManager واحد و ApplicationMaster واحد لكل تطبيق. يمكن أن يكون التطبيق إما وظيفة أو DAG للوظائف.
يحتوي ResourceManger على مكونين - المجدول و AppicationManager.
المجدول عبارة عن برنامج جدولة خالص ، أي أنه لا يتتبع حالة التطبيق قيد التشغيل. يخصص فقط الموارد لمختلف التطبيقات المتنافسة. أيضًا ، لا يقوم بإعادة تشغيل الوظيفة بعد الفشل بسبب فشل في الأجهزة أو التطبيق. يخصص المجدول الموارد بناءً على فكرة مجردة عن الحاوية. الحاوية ليست سوى جزء صغير من الموارد مثل وحدة المعالجة المركزية والذاكرة والقرص والشبكة وما إلى ذلك.
فيما يلي مهام مدير التطبيقات: -
- يقبل تقديم الوظائف من قبل العميل.
- Negotaites أول حاوية لتطبيق معين.
- إعادة تشغيل الحاوية بعد فشل التطبيق.
فيما يلي مسؤوليات ApplicationMaster
- يفاوض الحاويات من المجدول
- متابعة حالة الحاوية ومراقبة تقدمها.
يدعم الغزل مفهوم حجز الموارد عبر نظام الحجز. في هذا ، يمكن للمستخدم إصلاح عدد من الموارد لتنفيذ وظيفة معينة بمرور الوقت والقيود الزمنية. يتأكد نظام الحجز من أن الموارد متاحة للوظيفة حتى اكتمالها. كما يقوم بمراقبة الدخول للحجز.
يمكن للغزل أن يتعدى بضعة آلاف من العقد عبر اتحاد الغزل. يسمح اتحاد YARN بتوصيل مجموعة فرعية متعددة في الكتلة الضخمة المفردة. يمكننا استخدام العديد من المجموعات المستقلة معًا لوظيفة واحدة كبيرة. يمكن استخدامه لتحقيق نظام واسع النطاق.
دعونا نلخص كيف يعمل Hadoop خطوة بخطوة:
- يتم تقسيم بيانات الإدخال إلى كتل بحجم 128 ميجا بايت ثم يتم نقل الكتل إلى عقد مختلفة.
- بمجرد تخزين جميع كتل البيانات على عقد البيانات ، يمكن للمستخدم معالجة البيانات.
- ثم يقوم Resource Manager بجدولة البرنامج (المقدم من قبل المستخدم) على العقد الفردية.
- بمجرد معالجة جميع العقد للبيانات ، تتم إعادة كتابة الإخراج إلى HDFS.
لذلك ، كان هذا كله في كيفية عمل برنامج Hadoop التعليمي.
استنتاج
في الختام إلى How Hadoop Works ، يمكننا القول ، أن العميل يقدم أولاً البيانات والبرنامج. يخزن HDFS تلك البيانات ويقوم MapReduce بمعالجة تلك البيانات. الآن بعد أن تعلمنا مقدمة Hadoop وكيف يعمل Hadoop ،